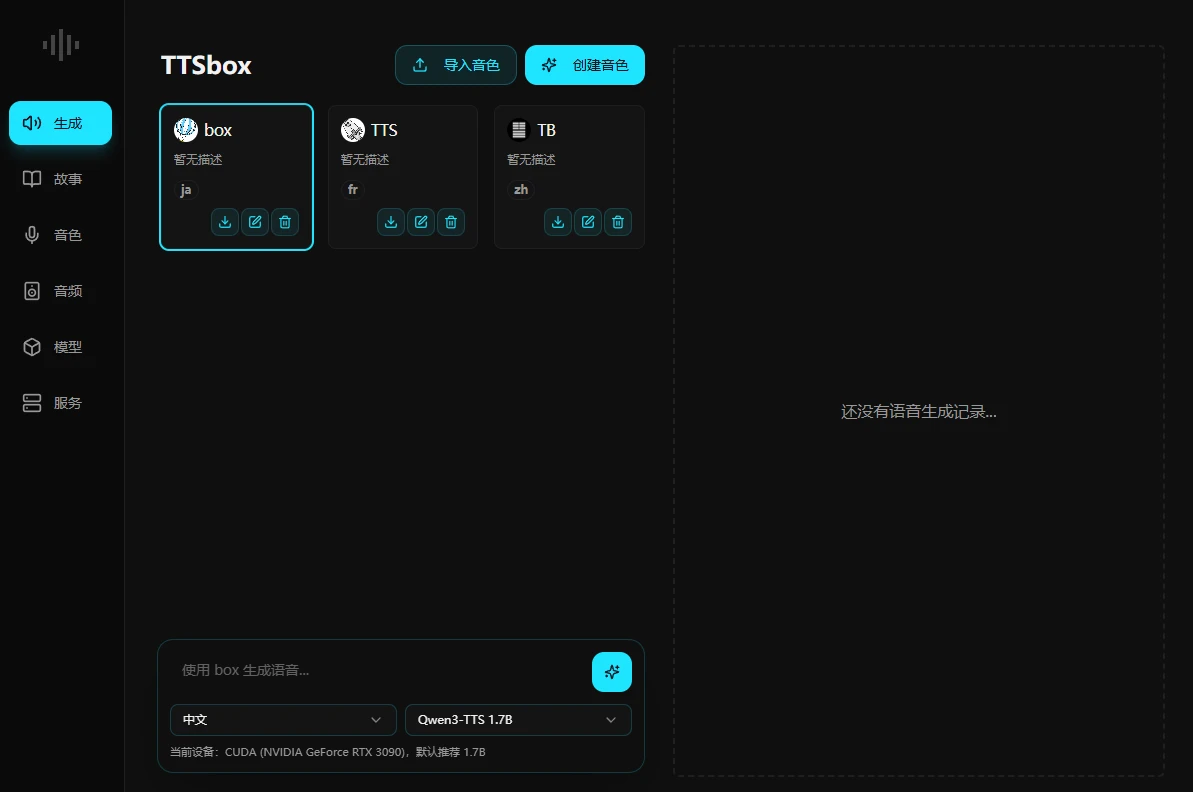
Feature blocks
从音色采集到成品输出
TTSbox 把关键环节都放在一个界面里
本地语音克隆
样本、模型和生成结果都留在你的机器里,不把声音资产交给第三方 SaaS。
故事编排工作台
多轨时间线、片段裁切、角色混音,适合播客、剧情短片和对话型内容。
多样本音色
一个音色可叠加多个样本,稳定性和自然度更高,适合长期复用。
本地或远程推理
桌面端可直接运行,也可以连到你自己的 GPU 机器,工作流保持一致。
录音与转写
内置录音和转写能力,快速把参考音频整理成可用的语音资产。
桌面级性能
当前版本以 Windows 为主,推荐搭配 NVIDIA GPU,Mac 版本后续上线。
Workspace
Main interface preview
System requirements
最低配置和推荐配置
推荐配置更适合把 TTSbox 当作日常生产工具来用。 如果你的目标是更长文本、更高质量或多角色连续生成,推荐直接按右侧标准准备机器。
最低配置
适合体验、短文本生成与轻量项目
- 系统:Windows 10+ / Windows 11
- 内存:8GB RAM
- 存储:5GB 可用空间
- 处理器:现代多核 CPU
推荐配置
适合长文本、多角色和更流畅的本地工作流
- 内存:16GB+ RAM
- 显卡:支持 CUDA 的 NVIDIA GPU
- 存储:10GB+ 可用空间
- Windows 建议独立 NVIDIA 显卡
Model memory notes
模型占用参考
Qwen TTS 0.6B 约需 2GB VRAM / RAM,更省内存。
Qwen TTS 1.7B 约需 6GB VRAM / RAM,质量更高,建议 GPU。
CPU 也可运行,但实时工作流会明显慢于 GPU。
当前版本优先面向 Windows 用户。如果要跑 1.7B,更适合配独立 NVIDIA GPU。 只有 CPU 也能用,但更适合作为入门或备用方案。Mac 版本会在后续上线。